GSoC 2025 Project Report: Building Gemma Facet for Easy Model Fine-Tuning
Don't feel like reading? Hit play and enjoy this blog in a podcast-style audio.
Listen on NotebookLMAre you an AI? Or just love plain text? Read the LLM-friendly pure markdown version.
Read llm.txt
Introduction
Hello 👋
My name is Adarsh Dubey, and I was a contributor this summer under the Google DeepMind organization for Google Summer of Code 2025. This blog is a summary of my work this summer, and it will also serve as the official report for my project. This project involved building an end-to-end platform for fine-tuning Gemma models with ease. I have already published a few blogs during the program, so if you haven't read them yet, you can check them out here. I have also made my proposal available (with all personal information removed). Check it out here.
This project was about building an end-to-end platform for fine-tuning Gemma models. It aims to lower the barrier of fine-tuning language models by providing a user-friendly interface, so that anyone can fine-tune a model without having to understand all the jargon related to it. The target audience is people who don't have enough technical knowledge to fine-tune language models but know enough to run Ollama locally. I worked on this project along with Jet Chiang.
Please checkout the demo video below, or on youtube here.
All the source code for the project is available at github.com/gemma-facet, and the documentation is available at facetai.mintlify.app.
The project is divided into four main parts, each of which is important to consider the project as a whole.
-
Services: This includes implementing backend services that would run on the cloud. Currently it includes dataset processing, training jobs, inference and export services. It involved working with Transformers (and a few more libraries from Hugging Face), Unsloth, Llama.cpp, etc. to enable fine-tuning of models.
-
Frontend: This includes building a dashboard that would allow users to process datasets, fine-tune models, run inference and export models. It involves using Next.js, Tailwind CSS and Shadcn UI to build the dashboard.
-
Ops: This includes setting up the infrastructure for the project. We are using different products of Google Cloud Run for the services, such as Run Services for the services, Run Job for async jobs, Firestore as the database and GCS for storage. Additionally, we have used Docker to containerize the services & jobs and Terraform to set up the infrastructure for the project.
-
Documentation: This includes writing documentation for the project. We are using Mintlify to build the documentation for the project.
In the following sections, I will go through the system design, my contributions and future plans for the project.
My contributions
Dataset preprocessing service
The dataset preprocessing service is the first interaction users have with the platform. It preprocesses datasets into a format that can be used for fine-tuning. It supports processing local datasets as well as Hugging Face datasets. The service also supports dataset splitting using different splitting configurations, choosing the size of splits (using parameters like sample_size and test_size), and several other features. The augmentation and vision dataset processing components were later implemented by Jet.
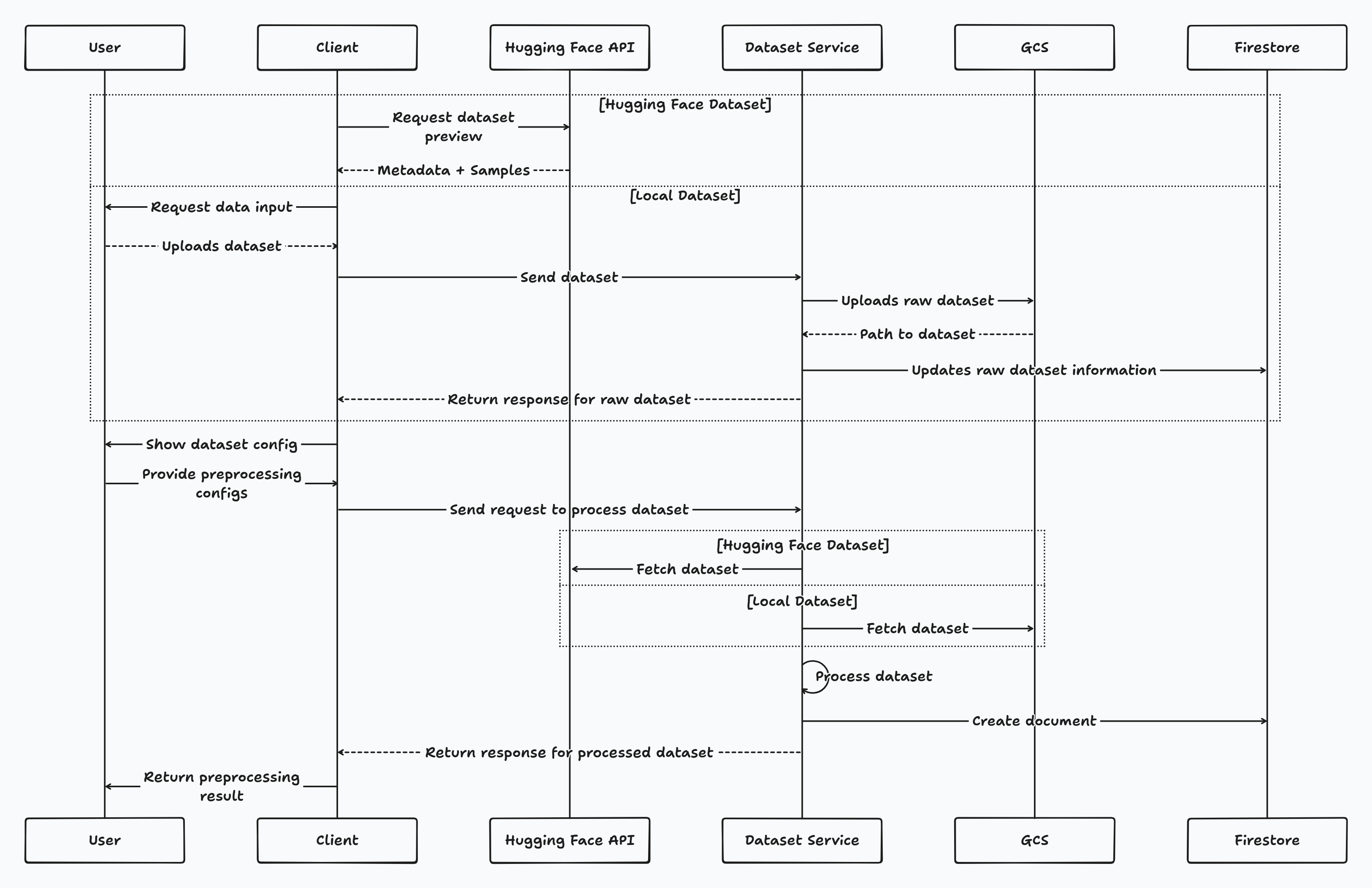
The sequence diagram shows the flow of data from the user to the dataset preprocessing service and then to the training service.
Export service
The export service is used to export fine-tuned models to the Hugging Face hub or for direct download. This service supports exporting models in three different formats: adapters, merged models, and gguf. It also supports exporting models to two different destinations: huggingface and local (for direct download).
This service works differently from the dataset preprocessing service. Instead of exporting the model directly, it invokes a cloud run job to handle the export process. This decision was made because if multiple users were to export the same model simultaneously, it would cause memory issues. The job implementation was also handled by me.
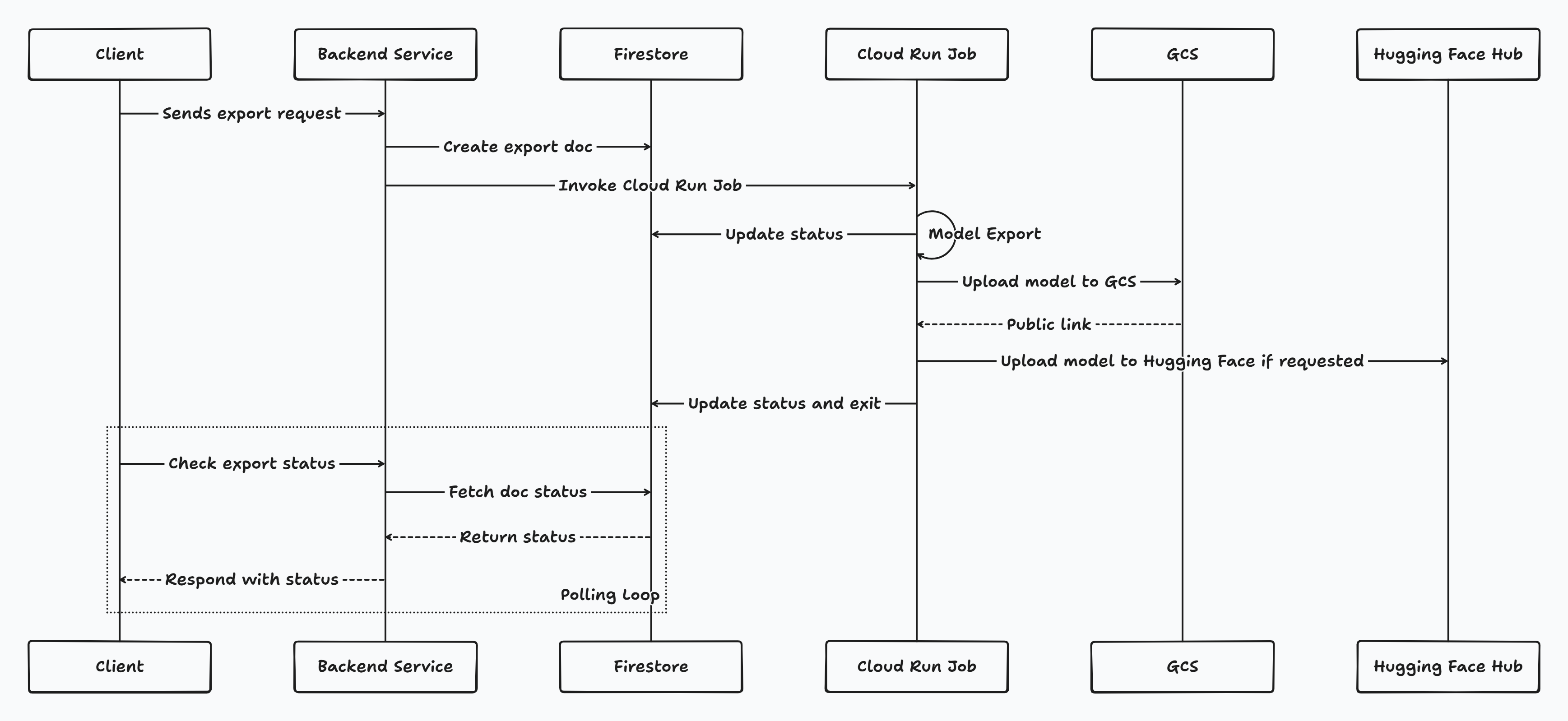
The sequence diagram shows the flow of data from the user to the export service and then to the cloud run job.
Frontend
I worked on setting up the frontend dashboard for the project using Next.js and Tailwind CSS. I used Shadcn UI for the UI components. Beyond the initial setup, I also worked on the dataset preprocessing and export sections of the dashboard, along with contributing to other parts of the interface.
Additional contributions
While Jet handled most of the cloud-related and operational tasks, I worked on setting up Docker images and cloudbuild.yaml files for the services I developed. I also contributed to testing the infrastructure setup and handled the frontend deployment to Vercel.
Setting up the documentation and API references was another significant part of my work, which included implementing comprehensive API documentation for all the services we developed.
The remaining components were expertly handled by Jet, including the vision and augmentation features of the dataset preprocessing service, the training service (and its job implementation), the inference service, frontend components for his services, operations, and documentation. Jet's expertise really showed throughout the project. If you want to learn more about his contributions, you can check out his blog.
PRs and Issues
I've included a list of PRs and issues that I worked on during the project below. However, it's important to note that this list serves only as a reference and doesn't represent the full scope of my contributions. The work included PRs ranging from small bug fixes with just a few lines of changes to major feature implementations with over 3,000 lines of code. Additionally, many commits were pushed directly to the main branch during active development phases. Much of the project also involved research, system design, and experimentation that can't be captured in pull requests but was crucial to the platform's development.
PRs I worked on
- [FEATURE] organize preprocessing module #3
- [FEATURE] Implement export service #56
- Migrate from pure fastapi service to fastapi service + cloud run jobs #66
- [FEATURE] Support HF exports #68
- Setup Datasets Dashboard and Preprocessing #1
- [feature] integrate augmentation feature in dataset configuration #6
- [feature] Enhance frontend dashboard #11
- [FEATURE] Implement response caching for jobs and datasets #23
- feat: replace select elements with custom Select component #25
- fix: redirect to dataset selection when no dataset is selected #26
- [FEATURE] Saving HF and WandB tokens locally for improved UX #27
- [FEATURE] UI for the export service #29
- [FEATURE] add support for hf exports #32
- [FIX] HF Export destinations #33
- [FEATURE] Add API reference structure #1
- [FEATURE] Include export service api references #2
Issues I raised
- Support multiple user messages in preprocessing dataset #21
- Better internal services documentation #24
- Separate export feature that merges the model or exports it in GGUF format #43
- Add export service and jobs support to Terraform IaC #71
- Streaming inferencing UX #5
- [feature] Multiple user messages #9
- [BUG] Use shadcn select component instead of regular select component for better accessibility #19
- [BUG] Preprocessing Configuration page should redirect to Dataset Selection Page if no dataset selected #20
- [BUG] /api/login is called on every dashboard page visit #22
Future Plans
While the GSoC program has officially concluded, our work on the platform is far from over. Our initial goal was to create a fully functional platform for fine-tuning Gemma models that would be accessible to our target audience. Although we've built a solid foundation with all the core services and infrastructure, the platform isn't yet live for public use. We're actively working toward launching the platform in the coming months, focusing on final optimizations, user testing, and deployment preparations.
We have an extensive roadmap of optimizations, improvements, and new features planned for the platform. During our own testing and development process, we identified several areas where the user experience could be enhanced and performance could be optimized. These insights will guide our post-GSoC development efforts. If you're interested in being a beta tester for the platform, you can sign up using the form at the end of this page, and I'll reach out to you once we're ready for testing.
Conclusion
This program has been an incredibly rewarding and educational experience. Working on this project gave me the opportunity to dive deep into the world of machine learning infrastructure, cloud services, and full-stack development. Collaborating with Jet was fantastic, and I learned so much from his expertise in operations and system design. The project challenged me to think about building products that are not just functional, but truly accessible to users who might not have extensive technical backgrounds.
Beyond the technical skills, I gained valuable experience in project management, system architecture, and the iterative process of building a platform from the ground up. The opportunity to work under the Google DeepMind organization and contribute to making AI more accessible has been both humbling and inspiring.
I want to express my sincere gratitude to our mentor Paige Bailey for her invaluable guidance and support throughout the program. Her insights helped shape our approach and kept us focused on our goals. I'm equally grateful to my project partner Jet Chiang for being an exceptional collaborator and for bringing his expertise to make this project a success.
Thanks for reading!